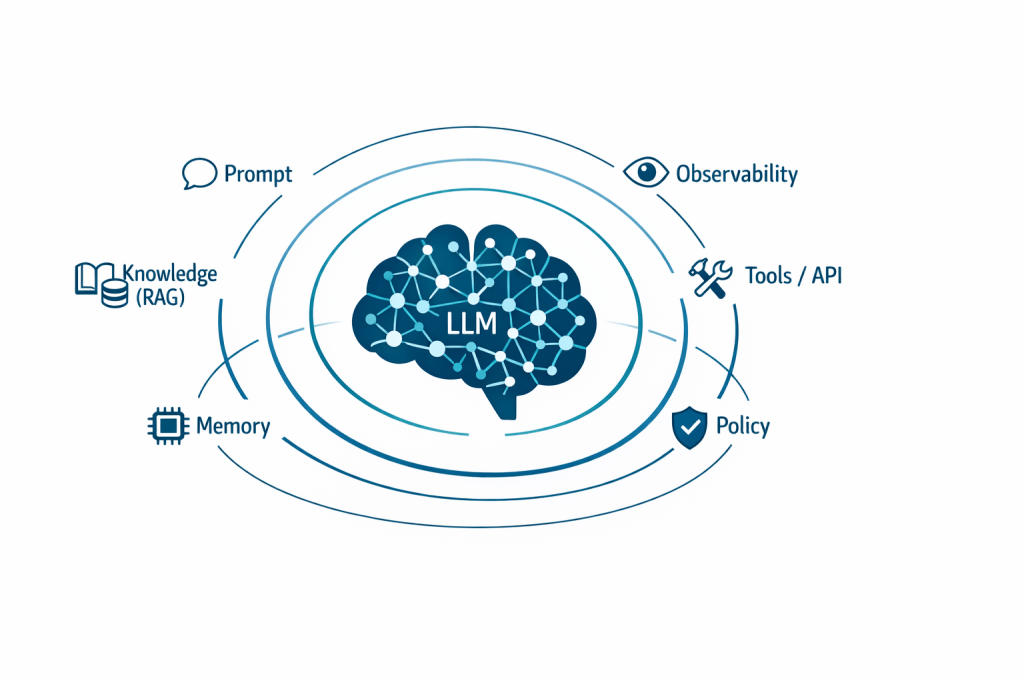
For years we have called “prompt engineering” the ability to get better results from language models by choosing the right words. Today, however, real applications (enterprise copilots, agents, RAG, multi-step workflows) reveal a clear limitation: it’s not enough to phrase the request well if the model doesn’t “see” the right information. This is where context engineering comes in: the systematic design of everything the model receives as input (instructions, knowledge, memory, tools, and constraints) to make it reliable in production.
Definitions: what Prompt Engineering and Context Engineering (really) are
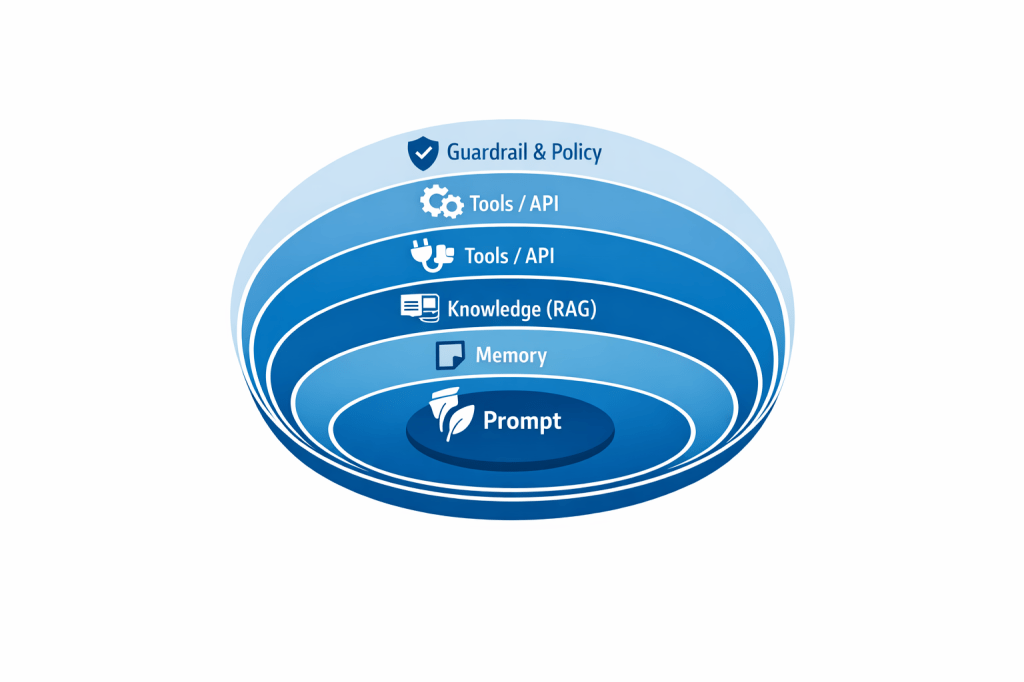
Prompt engineering is the set of techniques for writing effective instructions (the prompt) so that the LLM produces output consistent with the desired objective, tone, and format: task definition, constraints, examples, style, and response structure. It works very well when the problem is “contained” and the necessary information is already known or can be included directly in the prompt.
Context engineering is the discipline that designs and manages the entire input provided to the model during inference: not only the user’s question, but also the system prompt, policies, conversation history, retrieved documents (RAG), long-term memory, tool/API outputs, metadata, and constraints. In other words, it optimizes “what the model sees” and when it sees it, treating the context window as a scarce resource to fill with high-signal tokens. This is a shift in perspective, and in practice context engineering is becoming the key skill for bringing LLMs from demo to production.
- System instructions: role, tone, policies, boundaries (what to do and what to avoid).
- Knowledge: documentation, wikis, procedures, catalogs, product data (often via RAG).
- Memory: conversation summaries, user preferences, task state, past events.
- Tools: available functions and APIs, input/output schemas, permissions, selection logic.
- Structure: output templates, required fields, formats (JSON/Markdown), validations.
Key differences (scope, levers, risks)
| Aspect | Prompt engineering | Context engineering |
| Goal | Phrase the instruction as well as possible. | Ensure the model has the right information/resources to perform the task. |
| Unit of work | A prompt (or a prompt template). | A pipeline: retrieval, memory, tools, policy, compression, and orchestration. |
| When it “breaks” | When data is missing, continuous updates are needed, or the task is multi-step. | When retrieval and memory are weak, or the context is noisy (too many tokens) or inconsistent. |
| Core skills | Clarity, structure, examples, constraints, output formats. | Source selection/ordering, data quality, RAG, state and tool management, observability. |
| Typical outcome | More “well-written” and controllable output. | More grounded, stable, and repeatable output in production. |
What’s changing: from “clever” prompts to context-aware systems
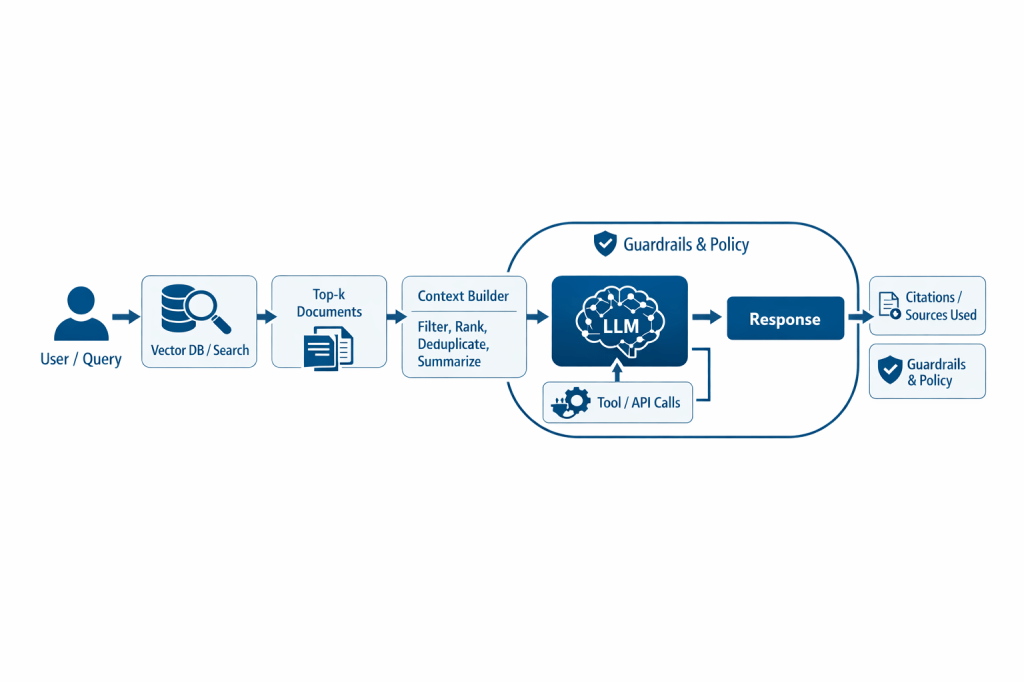
The shift from prompt to context is driven by an evolution in how LLMs are used: from one-shot chat to workflows and agents that plan, use tools, retrieve knowledge, and maintain state. In these scenarios, quality depends less on a “magic formula” in the prompt and more on:
- Access to up-to-date knowledge: models don’t “know” enterprise data; it must be provided.
- Context-window management: more context does not automatically mean better answers; selection and summarization are needed to avoid noise and unnecessary costs.
- Multi-turn and state: long conversations require memory (summaries, task state) and policies about “what to remember.”
- Tools and automation: when the model must choose and use tools (APIs, databases, systems), it needs descriptions, permissions, and execution control.
- Production reliability: quality becomes a system problem (data + orchestration + guardrails), not just a text problem.
Why you need both: it’s not “either/or”
Prompt engineering isn’t “dead”: it remains essential for expressing intent clearly, reducing ambiguity, and enforcing a format. But a prompt alone cannot bridge the gap between a model’s general capabilities and a domain’s specific needs: if facts or rules are missing, the LLM will tend to guess.
A good rule of thumb: the prompt tells the model what to do; the context makes the task realistically doable. For example, you can write a perfect prompt to “check whether a reimbursement is eligible,” but without an up-to-date policy and customer data (context) the output won’t be reliable. Conversely, having policies and data without a clear request and a controlled response format leads to verbose, inconsistent, or hard-to-automate answers.
When a prompt is enough—and when context engineering is needed
Prompt engineering (almost) sufficient when:
- the task is creative/editorial (rewrite, summarize text that is already provided);
- all necessary information is in the prompt or the attached document;
- the output does not need to be grounded in verifiable sources;
- the risk of error is low and the user always reviews.
Context engineering needed when:
- answers must reference up-to-date enterprise procedures, policies, or data (RAG);
- the system must operate across multiple steps (plan → execute → verify) or long conversations (memory);
- tools are required (CRM, ticketing, databases) and you must control how/how much they are used;
- you want to reduce hallucinations and increase repeatability, not just the “beauty” of the text;
- there are compliance, audit, and traceability constraints (what was used to answer).
Next steps: how to evolve from prompt to context engineering (a practical roadmap)
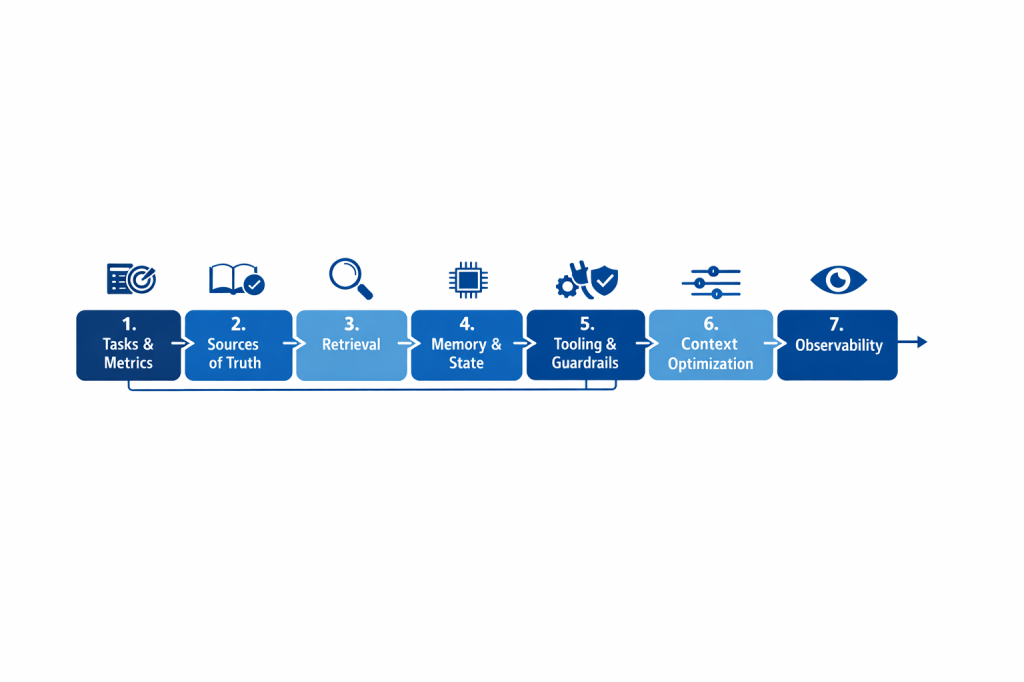
- Define tasks and quality criteria: what questions the system must handle, with which metrics (accuracy, groundedness, latency, cost, escalation rate).
- Map the sources of truth: documents, databases, and services that contain the correct facts (and who governs them).
- Design retrieval: chunking, metadata, ranking, version and user-context filters; make document selection repeatable.
- Introduce memory and state: differentiate “conversation history” (short-term) from “persistent memory” (preferences, entities, case state).
- Tooling and guardrails: clear tool descriptions, authorization policies, output validation, and error handling (retry, fallback, human-in-the-loop).
- Optimize the context window: order information, summarize, remove redundancies; avoid “dumping everything in.”
- Observability: log what was retrieved and passed to the model, measure failures, create evaluation datasets, and run continuous improvement loops.
Takeaway: a quick checklist
- If the problem is task clarity → work on the prompt (instructions, examples, format).
- If the problem is missing facts → work on the context (RAG, sources, versioning).
- If the problem is cross-turn inconsistency → add memory/state.
- If the problem is wrong actions → improve tooling and guardrails.
- If the problem is cost → optimize context selection and compression.
Conclusion
Prompt engineering remains the skill by which we “talk” to LLMs; context engineering is the engineering that makes them useful and reliable in the real world. The difference isn’t semantic: the level of intervention changes, from text to system. To build copilots and agents that generate business value, you need an integrated approach: clear, controllable prompts plus a context that is designed, updatable, and observable.
Boom, done 💣!
Follow me:

Leave a comment